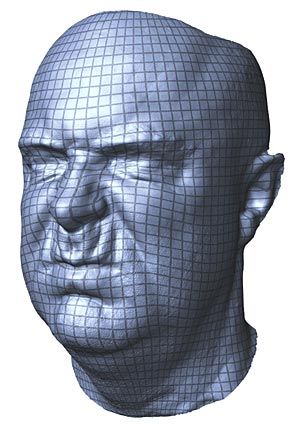
Um einen unangenehmen Effekt auf den Betrachter zu vermeiden, müssen Animationen von Menschen absolut realistisch sein. Um dieses Ziel zu erreichen, stattet beispielsweise Disney Research seine Figuren mit Details wie Poren und Fältchen aus.
Während Brian Amberg in eine kleine Webcam spricht, entsteht auf der Leinwand vor den Zusehern ein virtuelles Bild von ihm. Der frisch erzeugte Avatar ahmt Ausdruck und Grimassen seines realen Vorbilds in Echtzeit nach.
Gemeinsam mit seinem Kollegen von der Schweizer Universität École Polytechnique Fédérale de Lausanne, Mark Pauly, stellt Amberg eine Technik zur Gesichtsanalyse vor, mit der sich künftig jeder in der virtuellen Welt neu erschaffen könnte. Denn das animierte Ich muss dem realen keineswegs entsprechen, frei nach dem Motto: Du kannst alles sein, was du willst - sei es Mann, Frau oder Kermit der Frosch.
Neu an dieser Form der Gesichtsanalyse ist, dass sie mit verbreiteter Technik in vergleichsweise niedriger Auflösung möglich ist wie etwa mit herkömmlichen Webcams. Außerdem funktioniert sie ohne Marker - Sensoren, die am Gesicht selbst angebracht werden. Bisherige Technologien sind teuer, aufwändig und vor allem nicht in Echtzeit.
"Faceshift", wie sich die neue Technik nennt, erreicht Simultaneität, indem ein vorgefertigtes Modell an das reale Vorbild angepasst wird. Zu diesem Zweck verfügt das Modell bereits über einen Grundstock an Mimik wie etwa Lächeln oder Stirnrunzeln, der nur noch personalisiert und erweitert werden muss.
3-D-Modell lernt sprechen
Die technischen und praktischen Möglichkeiten von computergenerierten Gesichtern standen im Mittelpunkt des dritten Symposiums für Facial Analysis and Animation, das am Freitag im Wiener Museum of Young Art (Moya) stattfand. Gastgeber war das Forschungszentrum Telekommunikation Wien (FTW), das ebenfalls in der Thematik forscht und ein Projekt präsentierte.
Dabei soll ein sprechendes Gesicht synthetisiert werden, das heißt Lippen- und Gesichtsbewegungen werden simuliert, ohne dass dazu ein menschliches Vorbild nötig ist. "Zu diesem Zweck werden 3-D-Aufnahmen von Personen gesammelt, mit denen ein generisches Modell trainiert werden kann", sagt Michael Pucher vom FTW, einer der Forscher. Durch Auswertung der Daten lernt dieses Modell selbst zu sprechen. Ähnlich wie bei "Faceshift" kann ein solches Durchschnittsmodell für einen bestimmten Sprecher personalisiert werden.
Bisher wurde diese Technik der Synthetisierung in erster Linie für Sprache verwendet. Dazu werden entweder Einzelaufnahmen kombiniert, was einen eher abgehackten Effekt ergibt, oder ein Modell wird aus gesammelten Daten erstellt, das eigenständig sprechen kann.
Die Einsatzmöglichkeiten virtueller "Talking Heads" sind vielfältig, auch und vor allem im Servicebereich, von virtuellen Nachrichtenmoderatoren, die jeden gewünschten Artikel vorlesen, bis zu computergenerierten Steuerberatern.
Auch psychologisch erzielen Animationen Effekte, die im Service nutzbar sind. Jörn Ostermann von der Leibniz-Universität Hannover zitierte Studienergebnisse, laut denen ein freundliches Cartoongesicht das Vertrauen des Kunden in den vorgetragenen Text um dreißig Prozent erhöhte, das Verständnis bei Nebengeräuschen sogar um fünfzig Prozent.
Zu den größten Schwierigkeiten bei der Animation von Gesichtern gehört die Tatsache, dass Menschen von klein auf darauf trainiert sind, in Gesichtern zu lesen. Studien haben gezeigt, dass sich Menschen, basierend auf den Gesichtszügen ihres Gegenüber, innerhalb von 100 Millisekunden ein Urteil über dessen Vertrauenswürdigkeit bilden.
Verloren im "uncanny valley"
Es scheint logisch anzunehmen, dass animierte Figuren und Gesichter, je menschenähnlicher sie werden, vom Betrachter stärker akzeptiert werden. Dem ist nicht so. Tatsächlich werden Figuren, die zwar durchaus realistisch wirken, aber eben nicht völlig menschlich, mit großem Argwohn betrachtet.
Für die Gesichtsanimation bedeutet das, dass virtuell erzeugte Figuren und Gesichter entweder karikiert und künstlich wirken sollten, oder aber völlig lebensecht. Alles dazwischen wirkt auf den Betrachter unheimlich, erzeugt Ablehnung und liegt damit im sogenannten "uncanny valley", in einem unheimlichen Tal.
Wie dieses Tal überwunden werden kann, ist gerade für die Filmproduktion interessant. Die aufwändige Forschung, die beispielsweise Disney auf diesem Gebiet betreibt, demonstrierte Thabo Beeler von Disney Research Zürich, einer von zwei Forschungseinrichtungen des Konzerns.
In einem aufwändigen Prozess wird aus Fotos einer Person aus mehreren Blickwinkeln ein 3-D-Modell generiert. Dabei werden in mehreren Schritten nicht nur Gesichtszüge, sondern auch Poren, Fältchen und Barthaare, die separat errechnet und eingefügt werden, in den Computer übertragen. Schließlich entsteht auf dem Bildschirm ein absolut lebensechtes Bild. Auch irgendwie unheimlich. (Barbara Wallner, DER STANDARD, 26.9.2012)