Für Menschen ist es üblicherweise kein sonderliches Problem einzelne Stimmen aus einer Masse zu isolieren, und der richtigen Person zuzuweisen. Das ist bei Computern anders: Wer einen smarten Lautsprecher wie Amazon Echo oder Google Home nutzt, weiß dass für diese die Erkennung von Sprachbefehlen sehr schwer wird, wenn die Geräuschkulisse etwas lauter wird – etwa bei einer Party.
Zweiter Faktor
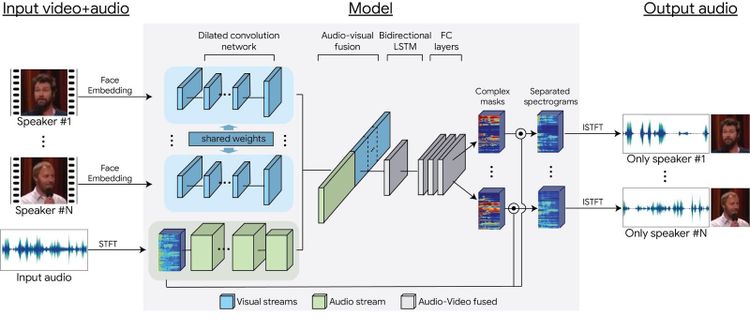
Forscher bei Google haben sich dieses Themas nun angenommen, und eine recht simple Lösung gefunden: Man holt sich nämlich zusätzlich Informationen über eine Kamera. Über Maschinenlernen erkennt das Google-System dabei wer gerade spricht, und kann infolge einzelne Stimmen von einander trennen.
Das Ergebnis ist durchaus beeindruckend, wie ein Testvideo zeigt. In diesem sprechen zwei Personen gleichzeitig, die Google-KI kann dabei den Tonfokus zur Gänze auf die eine oder andere Person wechseln, der Rest ist einfach nicht mehr zu hören.
Einsatzmöglichkeiten
Der Softwarehersteller verweist auf einige praktische Einsatzmöglichkeiten. So könnte die Technologie etwa bei Videochats zum Einsatz kommen, um die Stimme der primär sprechenden Person besser hervorzuheben – vor allem wenn diese gemeinsam mit anderen in einem Raum ist. Zudem könnte daraus aber auch eine neue Generation von optisch unterstützen Hörgeräten entstehen, die in lauten Umgebungen wesentlich besser funktionieren könnten als bisherige Lösungen, betonen die Forscher
Überwachung?
Es braucht aber nicht sonderlich viel Fantasie, um sich noch ganz andere Möglichkeiten einer solchen Technologie auszudenken. So könnte dies potentiell auch für großflächige Überwachung von Konversationen im öffentlichen Raum genutzt werden. Und auch sonst dürften längst nicht alle darüber glücklich sein, wenn sie von ihrem Gegenüber via Kamera erfasst werden – wie das Beispiel Google Glass in den letzten Jahren eindrucksvoll belegte. (apo, 13.4.2018)