Spätestens seit Donald Trump ist Weltpolitik via Twitter an der Tagesordnung. Doch die Tweets von Trump haben nicht nur politische und diplomatische Folgen, sondern beeinflussen durchaus auch ökonomische Größen. So erschreckte Trump im August 2019 mit einer Serie von Tweets zum Handelskonflikt mit China offensichtlich einige Investoren dermaßen, dass der Dow-Jones-Index an diesem Tag um 0,9 Prozent fiel. Dass gewisse Aussagen von politischen Entscheidungsträgern über Kanäle, die vor Jahren noch als nebensächlich galten, starken Einfluss haben können, ist mittlerweile kein Geheimnis mehr. Forschende beschäftigen sich inzwischen regelmäßig mit diesem Phänomen, sodass eine ausführliche Wikipedia-Seite geschaffen wurde, die rein der Analyse des Social-Media-Verhaltens von Trump gewidmet ist. Banker benutzen die Twitter-Aktivitäten von Trump sogar in Modellen, um zukünftige Aktienmarktbewegungen besser vorhersagen zu können. Allerdings müssen Sie nicht Präsident der Vereinigten Staaten (oder Elon Musk) sein, damit Ihr Internetverhalten Informationen für die Forschung liefert. Es reicht auch, einfach Google anzuwerfen.
Was man vorhersagen könnte
Eine wichtige Aufgabe der empirischen Wirtschaftsforschung ist das Vorhersagen von zukünftigen Entwicklungen. Wenn man allerdings darüber nachdenkt, scheint das Vorhersagen der Zukunft naturgemäß ein zum Scheitern verurteiltes Unterfangen zu sein. Nichtsdestotrotz ist die Erstellung von ökonomischen Vorhersagen ein Prozess von hohem wissenschaftlichen und politischen Interesse. Die Gesellschaft empfindet es als nützlich und wichtig, gewisse Vorkehrungen treffen zu können, wenn beispielsweise hohe Arbeitslosigkeit droht, Grippewellen vor der Tür stehen oder mit ungewöhnlich hohen Nächtigungszahlen im Tourismus zu rechnen ist. Modelle zu schaffen, mit denen wir zumindest eine Schätzung der Welt von morgen abgeben können, steht daher für viele Ökonomen auf der Forschungsagenda. Schwieriger als die statistische Maschinerie im Hintergrund ist es aber oft, überhaupt relevante Daten zu finden, die man in diese Modelle einspeisen kann. Idealerweise enthalten diese Daten nämlich gewisse Informationen über die Welt von morgen. Ein klassisches Beispiel dafür ist der sogenannte "Term Spread", ein Finanzmarktindikator, dessen Rückgang als "böses Omen" gilt, auf das wahrscheinlich eine baldige Rezession folgen wird.
In den letzten Jahren wird im Zuge der Suche nach relevanten Daten immer öfter auf Big Data zurückgegriffen. Vorhersagen basieren dementsprechend immer häufiger auf Informationen, die aus dem Internet stammen. Dieses immer stärker anwachsende Datenkonglomerat wächst allerdings nicht von selbst. Jede Person, die das Internet nutzt, trägt Informationen bei. Egal ob wir via Google das Netz durchsuchen oder unsere Meinung auf Twitter, Reddit oder Facebook von uns geben. Die bewussten und unbewussten Fußspuren, die wir oft tagtäglich im Internet hinterlassen, werden gesammelt, aggregiert und können dann – wenn man in etwa weiß, wo und wonach man suchen muss – relativ unkompliziert für Vorhersagen über die Welt von morgen aufbereitet werden.
"AMS" googeln – Arbeitslosigkeit wird steigen
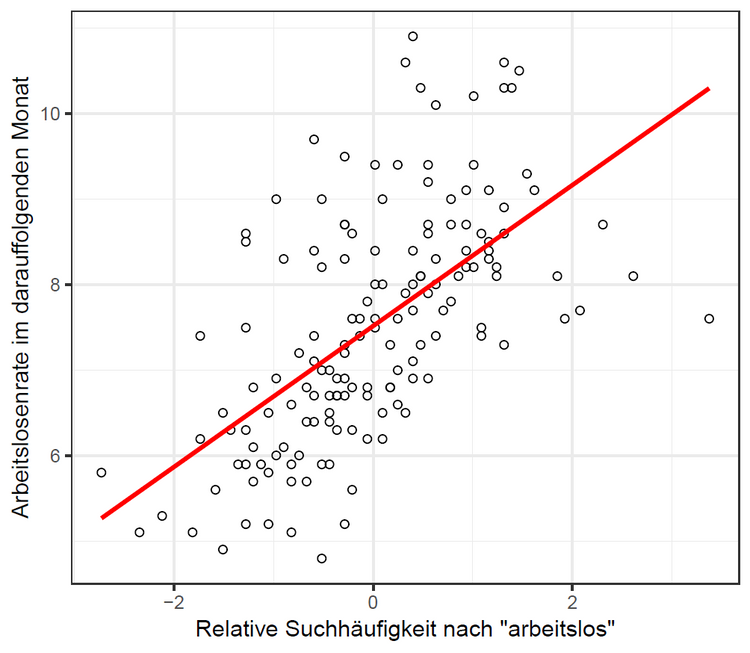
Stellen Sie sich beispielsweise vor, an Ihrem Arbeitsplatz wird angedeutet, dass Sie in absehbarer Zukunft Ihren Job verlieren werden. Die nächste Zeit ist für Sie höchstwahrscheinlich keine einfache. Viele werden im Zuge dieser Phase auf die Idee kommen, zwischendurch nach Wörtern wie "arbeitslos" oder "AMS" zu googeln, um entweder Meinungen und Erfahrungsberichte einzuholen oder schlicht die Adresse des nächsten AMS in Erfahrung zu bringen. Ein zutiefst menschlicher Vorgang, der allerdings auch Aufschluss über die nahe Zukunft geben kann. Vergleicht man beispielsweise die monatliche Häufigkeit von Google-Suchen nach "arbeitslos" in Österreich mit der Arbeitslosenquote des darauffolgenden Monats, findet sich ein deutlicher positiver Zusammenhang. Das bedeutet, dass die Häufigkeit von Suchanfragen im April dazu eingesetzt werden kann, präzisere Vorhersagen über die Arbeitsmarktsituation im Mai zu treffen – der Blick in die ökonomische Kristallkugel wird also etwas klarer.
Natürlich hinterlassen Sie aber nicht nur nützliches Datenmaterial, wenn Sie gerade kurz vor der Arbeitslosigkeit stehen. Haben Sie sich beispielsweise schon einmal dazu hinreißen lassen, Ihren Hausarzt durch Google zu ersetzen und Ihre Krankheitssymptome via Suchmaschine in den Äther zu schicken? Dann könnten Sie beispielsweise dazu beigetragen haben, dass Epidemiologen recht gut abschätzen können, ob im Land in der nächsten Zeit eine Grippewelle ansteht. Sie leisten nebenbei auch Ihren (übrigens unbezahlten) Beitrag zur besseren Planbarkeit von Nächtigungen im Tourismussektor, wenn Sie nach Hotels in einer Stadt googeln. Das haben unter anderem Kollegen von der tschechischen Nationalbank für Nächtigungszahlen in Prag nachgewiesen.
Stimmungen erkennen
Es werden allerdings nicht nur Suchanfragen von Usern im Netz für ökonomische Analysen verwendet. Viele von uns hinterlassen durch die alltägliche Internetnutzung auch weitaus subtilere Spuren, deren Fährte man in der Forschung aufnehmen kann. So lassen sich unter anderem Tools aus dem Bereich der Korpuslinguistik einsetzen, um auf Diskussionsplattformen die allgemeine Stimmung – das sogenannte "sentiment" – in Bezug auf gewisse Themen zu analysieren. Eine sehr einfache Variante ist, sich auszurechnen, wie oft in einer Twitter-Diskussion positiv konnotierte Wörter im Vergleich zu negativ behafteten Wörtern verwendet werden. Dieses extrahierte Twitter-Sentiment lässt sich dann zum Beispiel dazu verwenden, die Entwicklung der Aktienmärkte in naher Zukunft vorherzusagen. Erstmals hat diesen Zusammenhang der Experimentalpsychologe Johann Bollen mit seinem Team erforscht. Ihre Arbeit zeigt, dass die Stimmung auf Twitter unsere Vorhersagen über Finanzmarktentwicklungen deutlich verbessern kann.
Sollten altmodische Konzepte wie Aktien Ihnen weniger zusagen als neuartige Anlagemöglichkeiten wie Kryptowährungen, können Sie sich auch hier das Surfverhalten von Millionen von Usern zunutze machen. Normalerweise informieren sich Menschen nämlich bis zu einem gewissen Grad über Investitionen, bevor sie diese tätigen. Und wo könnte man sich besser informieren, als in der größten Online-Enzyklopädie der Welt? Freundlicherweise stellt Wikipedia das Klickverhalten der wissbegierigen Userinnen und User für Analysezwecke frei zur Verfügung. Und siehe da: Die Anzahl der Klicks auf Wikipedia-Seiten über Kryptowährungen lässt sich dazu einsetzen, den Marktpreis ebenjener Coins vorherzusagen.
Unendlich viele Daten pro Tag
Wie man sich leicht vorstellen kann, sind die Möglichkeiten der Analyse von Internetdaten damit noch lange nicht erschöpft. Nicht unerwähnt bleiben sollte, dass in diesem kurzen Artikel auf die Möglichkeiten, die beispielsweise hinter den 1,4 Millionen Swipes auf Tinder, die in jeder Minute getätigt werden, überhaupt nicht eingegangen wird. Oder auf die 55.140 Fotos, die alle 60 Sekunden auf Instagram hochgeladen werden. Oder auf die 4,5 Millionen Youtube-Videos, die gut 9.700 Uber-Fahrten oder die knapp 695.000 Streaming-Stunden auf Netflix, die uns im Minutentakt neue Forschungsperspektiven eröffnen.
Je mehr der gesellschaftliche Alltag von Onlineplattformen vereinnahmt wird, desto eher lassen sich aus den resultierenden Daten Schlussfolgerungen über menschliches Verhalten ziehen. Die mehr als 4,3 Milliarden User des Internets erzeugen jeden Tag Milliarden und Abermilliarden Bytes an rohem Datenmaterial – Tendenz explosiv steigend. Im Jahr 2020 wird diese unvorstellbare Datenmenge Schätzungen zufolge 40-mal mehr Bytes beinhalten, als Sterne im beobachtbaren Teil des Universums existieren. Die Forschung mit diesen Daten schraubt im Vergleich dazu noch an ihren ersten, primitiven Teleskopen. Fest steht, dass sie mit jedem neuen Stück Information im Internet an Bedeutung gewinnen wird. (Gregor Zens, 17.12.2019)
