Resultat: "Ozymandias" von Percy Shelley
Resultat: "Hamlet"-Zusammenfassung eines Schülers.
Resultat: Einfache KI-Version der "Hamlet"-Zusammenfassung.
Resultat: Komplexere KI-Version.
So wie Bilder-KIs seit Monaten für Diskussionen rund um Kunst und Copyright sorgen, sorgte die Veröffentlichung von Chat GPT 3 nun für Debatten rund um die Unterscheidbarkeit zwischen Texten von Mensch und Maschine. Denn das eigentlich auf geschriebene Unterhaltungen spezialisierte System kann nicht nur chatten, sondern beherrscht auch allerlei andere Textformen – und das mitunter erstaunlich gut.
Das birgt neben dem Einsatz als Inspirationshilfe gegen Schreibblockaden oder Unterstützung beim Verfassen von Marketingtexten freilich auch Missbrauchspotenzial– mit dem sich auch manche Lehrer bereits auseinandersetzen müssen. Sie haben seit kurzem einen neuen Verbündeten, nämlich den Princeton-Studenten Edward Tian. Sein Analysetool GPT Zero soll KI-Texte entlarven.
Großes Interesse
Entstanden ist das Werkzeug an den vergangenen Weihnachtsfeiertagen. Als Motivation gibt Tian den Anstieg an KI-gestütztem Plagiarismus an. Bedarf scheint bereits reichlich vorhanden zu sein. Am 3. Jänner stellte er sein Werkzeug vor. Seitdem hat er nach eigenen Angaben zahlreiche Anfragen von Lehrkräften rund um die Welt erhalten. Sein Tweet wurde bislang über sieben Millionen Mal angezeigt.
Dass es wohl einiges Interesse an GPT Zero gibt, zeigte sich auch im Rahmen des Tests. Denn die meisten Versuche, die App aufzurufen, endeten mit Timeout-Meldungen, die auf eine Überforderung der Server der App-Hosting-Plattform Streamlit hinweisen.
Funktionsweise
Das ebenfalls KI-basierte Werkzeug nutzt in seinem Modell zwei Kernattribute, um zwischen einem von einem Menschen verfassten und einem von einer KI generierten Text zu unterscheiden: "Verworrenheit" (perplexity) und "Ruckartigkeit" (burstiness). Beide werden bei der Ausführung des Tools kurz erklärt.
"Verworrenheit" beschreibt die Zufälligkeit von Textelementen, die bei KI-Werken tendenziell niedrig ist. Da aber auch von Menschen Geschriebenes mit wachsendem Umfang an Zufälligkeit abnimmt, misst GPT Zero einen Durchschnitt pro Satz anhand der 345 Millionen Parameter des Chat-GPT 3-Vorgängers Chat GPT 2. Der Endwert ergibt eine Zahl, die aussagt, wie viele Texte mit niedrigerer "Verworrenheit" wahrscheinlich von einer KI erzeugt würden. Je höher dieser Wert ist, desto höher ist gemäß dieser Logik auch die Wahrscheinlichkeit, dass das analysierte Werk menschengemacht ist.
"Ruckartigkeit" hingegen beschreibt das Auftreten "untypischer" Elemente in zufällig verteilten Blöcken. Das Auftreten solcher Cluster sei für von Menschen verfasste Texte typisch. Allerdings weist neuere Forschung laut Tian darauf hin, dass auch manche von Menschen geschriebenen Sätze niedrige "Ruckartigkeit" aufweisen können. KI-Werke fallen aber generell mit konstant niedriger "Ruckartigkeit" und recht gleichmäßiger Verteilung von untypischen Elementen auf.
Probelauf
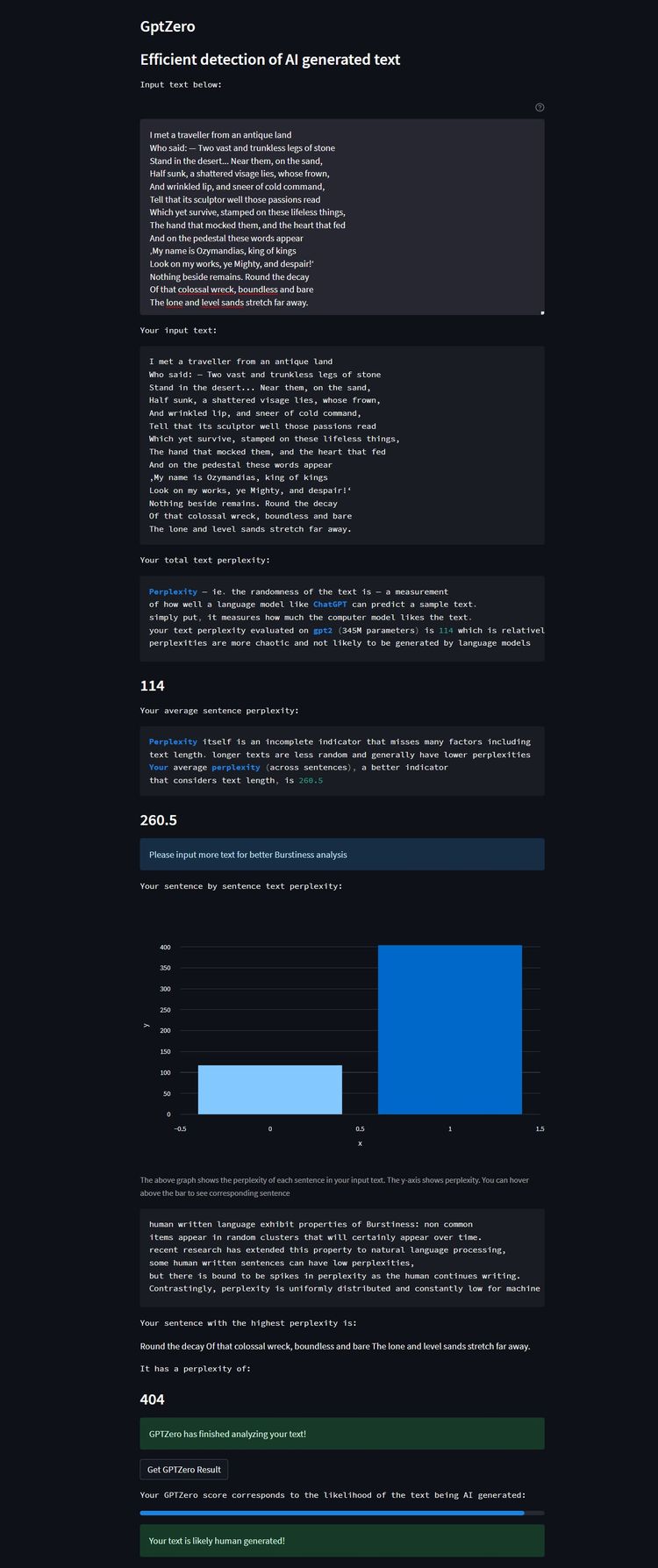
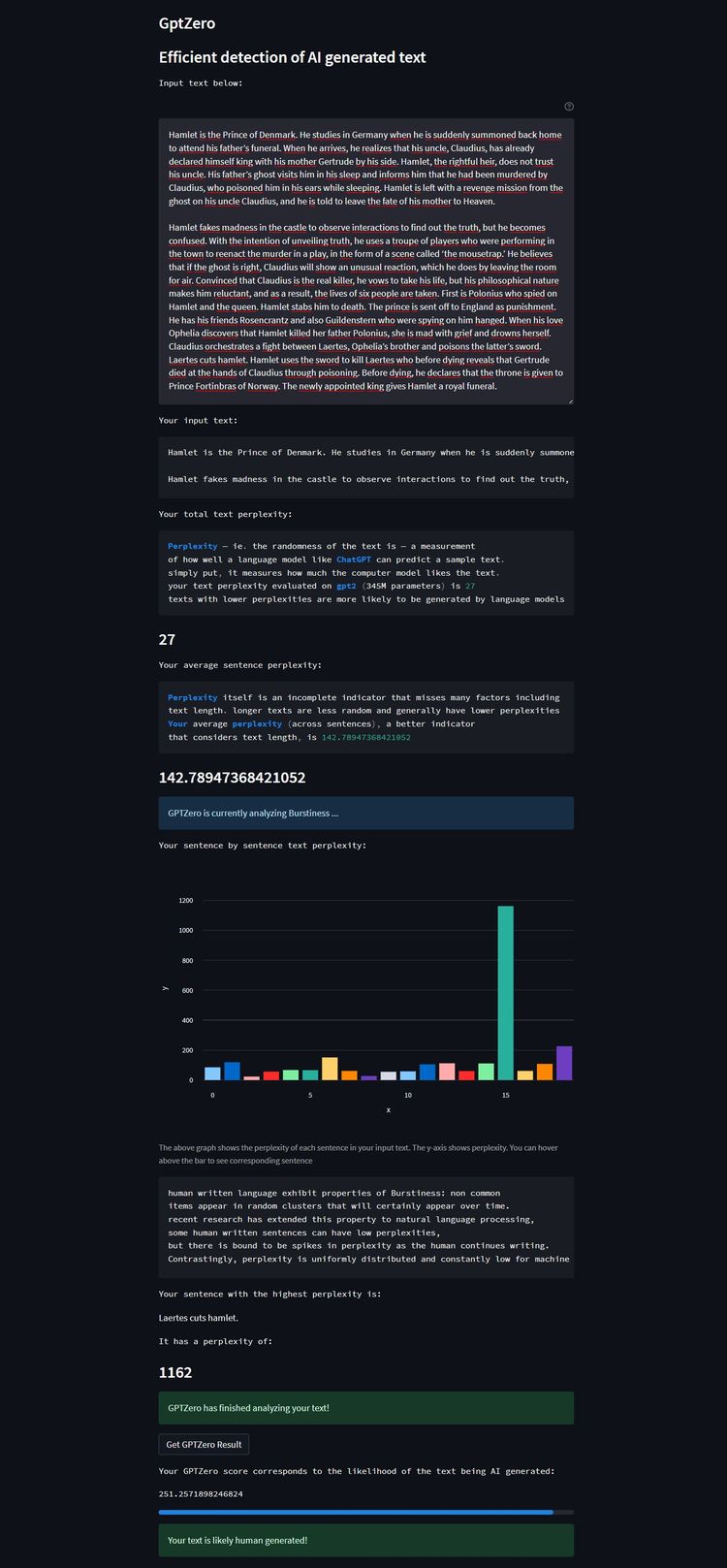
DER STANDARD hat das Tool einer Stichprobe unterzogen. Dafür wurde GPT Zero mit drei Texten konfrontiert. Für den Lackmustest mit einem Gedicht, das in jedem Fall als menschengemacht erkannt werden sollte, wurde "Ozymandias" von Percy Shelley herangezogen. Zudem wurde eine auf Summary Story publizierte, von einem Schüler erstellte Zusammenfassung von Shakespeares "Hamlet" eingespeist. Zur Gegenprobe wurde das Werkzeug schließlich mit zwei Zusammenfassungen aus der Feder der Text-KI Chatsonic gefüttert.
Bei "Ozymandias" stellte GPT Zero erfolgreich hohe Varianz im Geschriebenen fest und identifizierte das Gedicht korrekt als "wahrscheinlich von einem Menschen erstellt". Ebenso erkannte es ausreichend Unregelmäßigkeiten in der Schülerversion der "Hamlet"-Zusammenfassung, um diese als wohl menschliches Erzeugnis einzustufen.

KI vs. KI
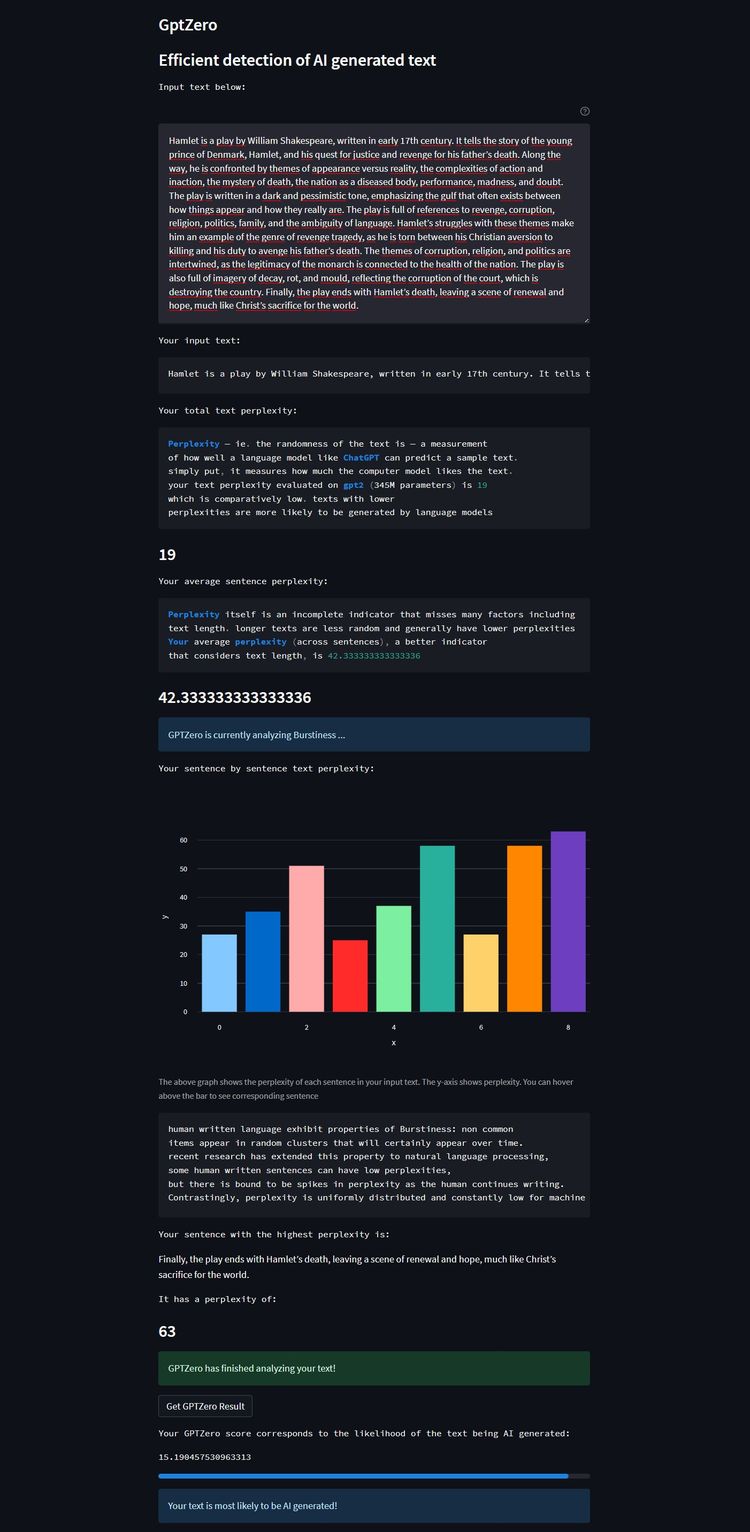
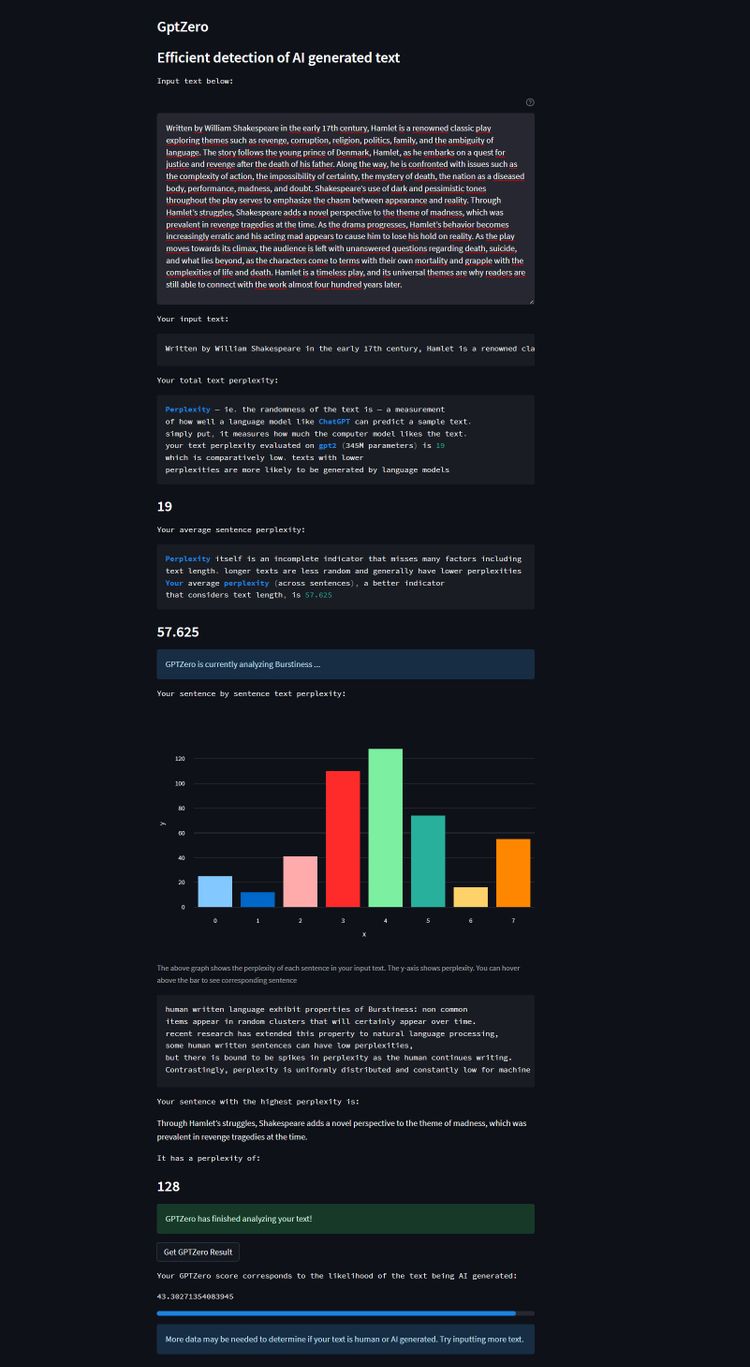
Die erste KI-Version, bei der Chatsonic schlicht um eine Zusammenfassung gebeten wurde, klassifizierte GPT Zero korrekt als Maschinentext. Gemäß der Analyse fehlte es dem Geschriebenen an den notwendigen Fluktuationen in puncto Varianz zwischen den einzelnen Sätzen. Für die zweite Probe wurde die KI allerdings explizit um "längere, komplexere, stark variierende Sätze" gebeten, um zu sehen, ob sich der Software-Detektor damit einfach austricksen lässt.
Für das Erzeugnis stellte das Prüfwerkzeug erneut eine niedrige "Verworrenheit" im Gesamtwerk fest, allerdings eine durchschnittliche Varianz der einzelnen Sätze. Dementsprechend konnte es keine eindeutige Tendenz feststellen. Anstelle einer Einschätzung erklärte GPT Zero, dass "womöglich mehr Daten notwendig" seien, um ein abschließendes Resultat zu liefern. Dies legt – wenn auch nur mit einem Einzelbeispiel – nahe, dass es durchaus gelingen kann, die Software an der Nase herumzuführen.
(Noch) nicht verlässlich
Das Tool hat auch darüber hinaus klare Limitationen. Die offensichtlichste ist, dass es Texte nicht auf Kontext prüft, sondern eben nur Schreibmuster analysiert. Ob die Zusammenfassung von "Hamlet" tatsächlich dem Inhalt des Shakespeare-Klassikers entspricht, beantwortet sie nicht. Dabei neigen Chat GPT und Konsorten gerade hier immer wieder zu Fehlern. Aktuelle Fragen kann Chat GPT beispielsweise gar nicht beantworten, da es keine Internetsuchen durchführt und sein Lernmaterial zum größten Teil aus Inhalten besteht, die vor 2022 erstellt wurden.
Aber auch an der Umsetzung wird Kritik geübt, wie etwa hier in einer Diskussion auf Reddit. Bemängelt wird, dass hier nicht mit einem "supervised learning"-Modell gearbeitet wird. Ein solches baut auf von Menschen klassifizierten Datensätzen auf, die einer KI beispielsweise helfen, Gegenstände auf Fotos oder Spam-Mails von "echter" elektronischer Post zu unterscheiden. Dies ermöglicht der KI, ihre eigene Genauigkeit einzuschätzen und mit der Zeit selbstlernend besser zu werden.
Bei "unsupervised learning" überlässt man die Einordnung von Datensätzen dem Maschinenlern-Algorithmus der KI selbst. Das verringert den Aufwand für Entwickler und ist oft nützlich, um Korrelationen zwischen Daten zu finden. Allerdings ist dieser Zugang nicht gut für Voraussagen geeignet und kann mitunter "extrem inakkurate" Ergebnisse produzieren, wie es IBM in einem erklärenden Blogposting zusammenfasst.
Ausblick
Grundsätzlich ist es möglich, KI praktisch mit ihren eigenen Waffen zu schlagen und sich ihren Lernprozess zu eigen zu machen, um Erkennungssysteme umzusetzen. Allerdings sind die Ergebnisse von GPT Zero nicht als zwingend vertrauenswürdig einzustufen. Sie müssen von Menschen überprüft werden, was gerade für Lehrkräfte, die noch keine Erfahrung mit Text-KIs haben, keine realistisch lösbare Aufgabe ist. Selbst jene, die sich mit der Materie beschäftigen, sollten Urteile nicht allein auf Basis dieser automatisierten Analyse fällen. Denn so besteht die Gefahr, einer Falscherkennung aufzusitzen und einen Schüler zu Unrecht einer Fälschung zu bezichtigen.
Ungeachtet dessen hat die "Anti-Text-KI" laut Tian auch schon das Interesse von Investoren auf sich gezogen. Die Kommerzialisierung hat auch bereits begonnen. Ein verbessertes Modell ist in Entwicklung, und auf der Website des Projekts bietet man bereits eine Warteliste für interessierte Schulen und Lehrkräfte an. Die erste Version wurde in "GPT Zero Classic" umgetauft und soll langfristig kostenlos online verfügbar bleiben. (gpi, 10.1.23)