Am 5. März 2024 erlebte die Website derStandard.at eine technische Störung, die circa zwischen 13:05 und 13:55 Uhr zu eingeschränkter Erreichbarkeit in bestimmten Bereichen führte. Davon betroffen waren allerdings nur bestimmte User:innen und bestimmte Bereiche, da der Großteil durch unser Content Delivery Network (CDN) ausgeglichen wurde. In diesem Blog-Post wollen wir einen Einblick in die Ursachen ("Root Cause Analysis") und die Lösung geben.
Hintergrund
Das Web-Frontend von derStandard.at ("EditorialWeb") lädt viele redaktionelle Inhalte (jedoch zum Beispiel nicht das Forum) von der sogenannten Content Store API. Diese Content Store API ist durch ein vorgeschaltetes AWS API Gateway erreichbar, das sich auch um die Autorisierung der API Requests kümmert.
Das API Gateway ruft dabei eine AWS Lambda ("Lambda Authorizer") auf, die validiert, ob der Request von einem autorisierten Frontend (EditorialWeb, LiveContent Backend, u. a.) erfolgt. Dabei verwendet der von uns entwickelte Lambda Authorizer den AWS Secret Manager, um einen Key zu laden – und dann den Request zu autorisieren, bevor der jeweilige Client die Content Store API nutzen kann.
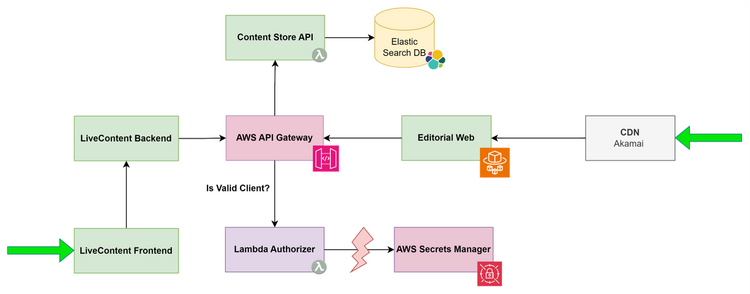
Was ist passiert?
Betroffene Bereiche
Good News: Die meisten Leser:innen waren von diesem Ausfall nicht betroffen, da unser Content Delivery Network (CDN) das EditorialWeb cached und beim Ausfall der "Origin Server" weiterhin die gecachte Version auslieferte. Somit waren für die Zeit während des Ausfalls der Content Store API keine neuen Artikel oder Änderungen auf der Startseite sichtbar. Die gecachte Version der Startseite von 12:56, sowie die Detailseiten der bestehenden Artikel wurde aber weiterhin vom CDN ausgeliefert.
Bestimmte Inhalte wie zum Beispiel der Livebericht haben eine unterschiedlich konfigurierte CDN Cache-Policy, weshalb diese Bereiche früher sichtbar betroffen waren. Forum, Notifications, Abos und andere Bereiche sind in anderen Microservices abgebildet und waren überhaupt nicht betroffen.
Lösung und Prävention
Durch Monitoring der Endpunkte wurde das Team sofort via automatischem Alert über die Probleme informiert. In so einem Fall wird eine "Incident Bridge" – ein Live-Chat beteiligter Techniker:innen aus unterschiedlichen Bereichen (Software Engineering, Cloud Plattform, Netzwerk-Infrastruktur, Interne IT) eingerichtet. In dieser Incident Bridge wurde gemeinsam analysiert, was die Ursache des Problems und was mögliche Lösungen wären.
Gemeinsam wurde gegen 13:40 folgende erfolgreiche Lösung identifiziert: Der Lambda Authorizer wurde manuell restarted, um so das Caching dort zurückzusetzen.
Beim Neustart funktionierte der Aufruf des AWS Secrets Manager Services wieder wie immer, das EditorialWeb konnte sich dadurch wieder erfolgreich bei der Content Store API authentifizieren und das CDN konnte eine aktualisierte Version der Seiten vom EditorialWeb ausspielen und cachen.

Um zukünftige Probleme zu vermeiden, wurde der Code im Lambda Authorizer mit einer Retry-Logik inklusive exponentiellem Back-off ergänzt, die im wirklich seltenen Falle eines erneuten Fehlers des AWS Secrets Managers greifen soll.
Engineering Fazit
Dieser Vorfall unterstreicht die Bedeutung von robusten Fehlertoleranzmechanismen in der Softwareentwicklung.
Eine Verkettung verschiedener Ursachen hat zu dem Problem geführt. Durch Redundanz – die Nutzung eines Content Delivery Networks mit Caching – war es allerdings möglich, die Auswirkung auf User:innen gering zu halten.
Die verbesserte Implementierung des Lambda Authorizers mit Retry-Logik inklusive exponentiellem Backoff stärkt die Resilienz unserer Systeme weiter und verringert die Wahrscheinlichkeit zukünftiger Ausfälle. Dies ist gerade in Auxiliary-Services wie dem Lambda Authorizer wichtig, da diese kleinen Dienste die Auslieferung blockieren können.
Test-Frameworks wie Chaos Monkey könnten helfen, auch unwahrscheinliche Service-Ausfälle zu simulieren – und den resilienten Umgang mit diesen Ausfällen zukünftig besser zu überprüfen.
Finally: Ein Neustart (in diesem Fall des Lambda Authorizers) war wieder mal die Lösung ;-) (Max Knor, 15.3.2024)